Publication info
-
 Neural Information Processing Systems 2023
Neural Information Processing Systems 2023
Overview
In this work, we propose using Video Prediction Rewards (VIPER) for reinforcement learning. VIPER first learns a video prediction model from expert videos. We then train an agent using reinforcement learning to maximize the log-likelihood of agent trajectories estimated by the video prediction model. Directly leveraging the video model’s likelihoods as a reward signal encourages the agent to match the video model’s trajectory distribution. Additionally, rewards specified by video models inherently measure the temporal consistency of behavior, unlike observation-level rewards. Further, evaluating likelihoods is significantly faster than performing video model rollouts, enabling faster training times and more interactions with the environment.
We summarize the three key contributions of this paper as follows:
- We present VIPER: a novel, scalable reward specification algorithm which leverages rapid improvements in generative modeling to provide RL agents with rewards from unlabeled videos.
- We perform an extensive evaluation, and show that VIPER can achieve expert-level control without task rewards on 15 DMC tasks, 6 RLBench tasks, and 7 Atari tasks.
- We demonstrate that VIPER generalizes to different environments for which no training data was provided, enabling cross-embodiment generalization for tabletop manipulation.
Along the way, we discuss important implementation details that improve the robustness of VIPER. The project page is organized as follows:
- Overview
- Leveraging Video Prediction Rewards for Reinforcement Learning
- Benchmarks
- Cross-Embodiment Generalization
- Visualizing Video Model Uncertainty
Leveraging Video Prediction Rewards for Reinforcement Learning
Video Modeling
Our method can integrate any video model that supports computing likelihoods over the joint distribution factorized in the following form:
\[\log p(x_{1:T}) = \sum_{t=1}^T \log p(x_t\mid x_{1:t-1}),\]where \(x_{1:T}\) is the full video consisting of \(T\) frames, \(x_1,\dots,x_T\).
In this paper, we use an autoregressive transformer model based on VideoGPT as our video generation model. We first train a VQ-GAN to encode individual frames \(x_t\) into discrete codes \(z_t\). Next, we learn an autoregressive transformer to model the distribution of codes \(z\) through the following maximum likelihood objective:
\[\max_{\theta} \sum_{t=1}^T \sum_{i=1}^Z \log p_\theta(z^i_t \mid z^{1:i-1}_t, z_{1:t-1}),\]The resulting video model is able to produce videos that capture the complex dynamics and behaviors in each environment. For example, a single task-conditond video model trained on 45 RLBench tasks across two arms produces rollouts which accurately model each task:

Reward Formulation
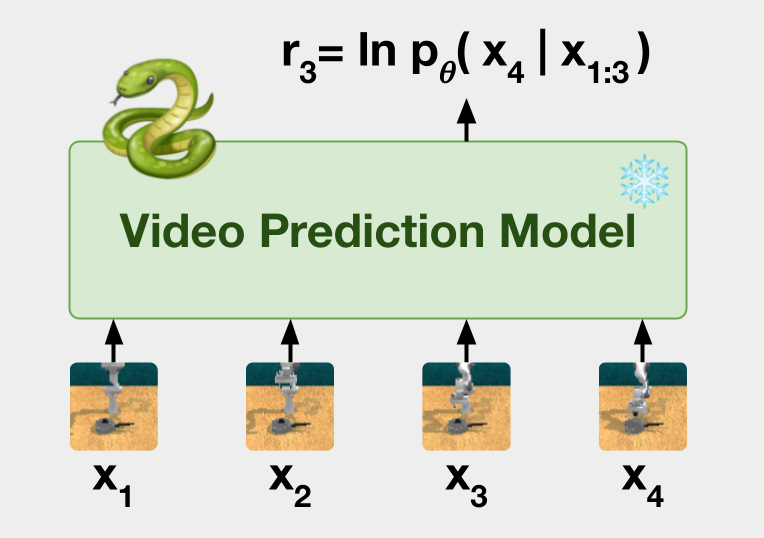
Given a pretrained video model, VIPER proposes an intuitive reward that maximizes the conditional log-likelihoods for each transition \((x_t, a_t, x_{t+1})\) observed by the agent:
\[r^{\mathrm{VIPER}}_t \doteq \ln p_\theta(x_{t+1}|x_{1:t}).\]This reward incentivizes the agent to find the most likely trajectory under the expert video distribution as modeled by the video model. However, the most probable sequence does not necessarily capture the distribution of behaviors we want the agent to learn.
For example, when flipping a weighted coin with \(p(\text{heads} = 0.6)\) 1000 times, typical sequences will count roughly 600 heads and 400 tails, in contrast to the most probable sequence of 1000 heads that will basically never be seen in practice. Similarly, the most likely image under a density model trained on MNIST images is often the image of only background without a digit, despite this never occurring in the dataset. In the reinforcement learning setting, an additional issue is that solely optimizing a dense reward such as \(r^{\mathrm{VIPER}}_t\) can lead to early convergence to local optima.
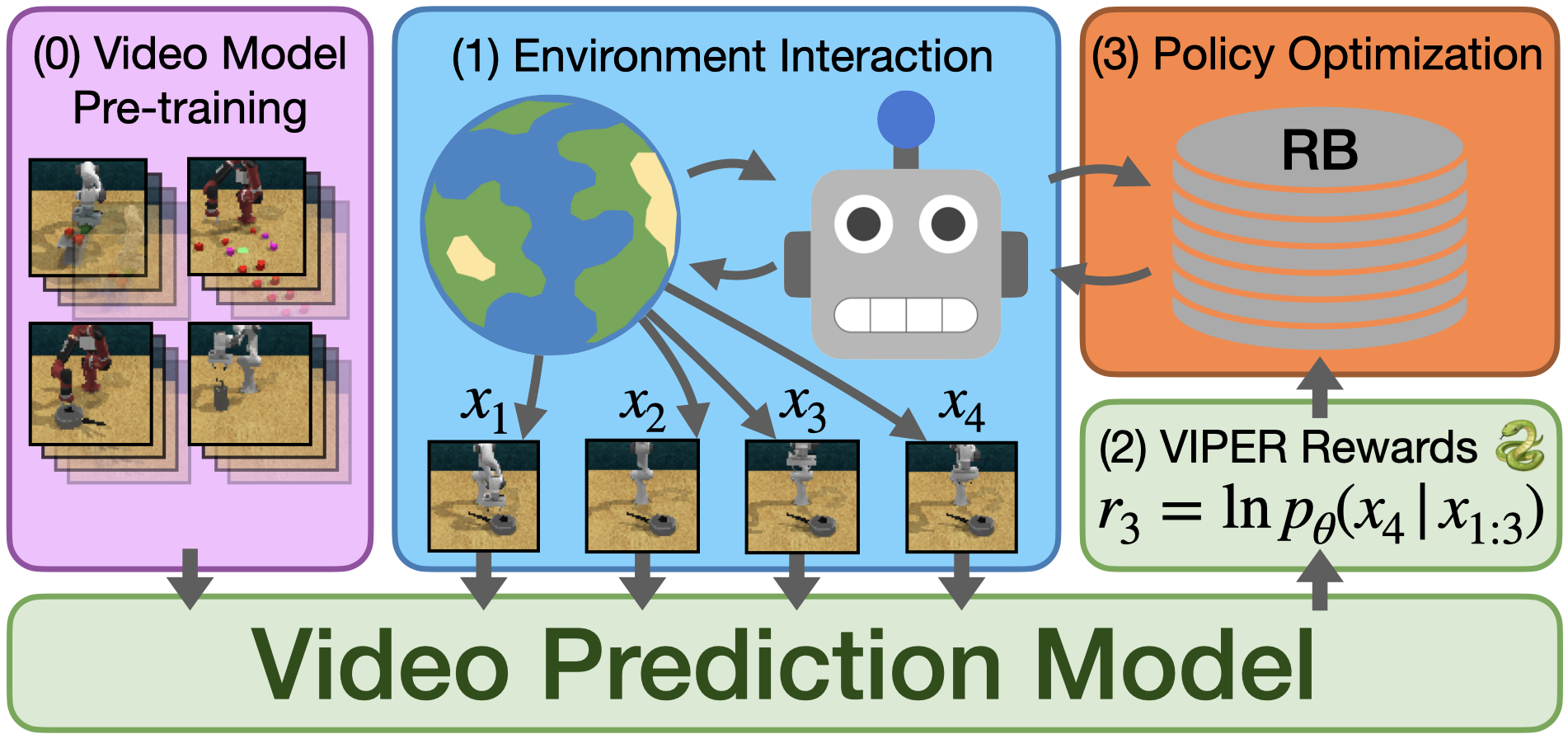
To overcome these challenges, we take the more principled approach of matching the agent’s trajectory distribution \(q(x_{1:T} )\) to the sequence distribution \(p_\theta(x_{1:T} )\) of the video model by minimizing the KL-divergence between the two distributions. We refer the reader to the main text for all derivations. The resulting reward is given by:
\[r^{\mathrm{KL}}_t \doteq r^{\mathrm{VIPER}}_t+\beta r^\mathrm{expl}_t,\]Where \(\beta\) balances the relative importance of the VIPER and exploration rewards. We summarize VIPER in the figure below:
Benchmarks
We evaluate using VIPER rewards for policy learning on 15 tasks from the DeepMind Control Suite, 7 tasks from Atari Gym, and 6 tasks from the Robot Learning Benchmark. Aggregate plots of the results are shown below. We compare VIPER to Adversarial Motion Priors, and to a Task Oracle with access to full state information and task reward.
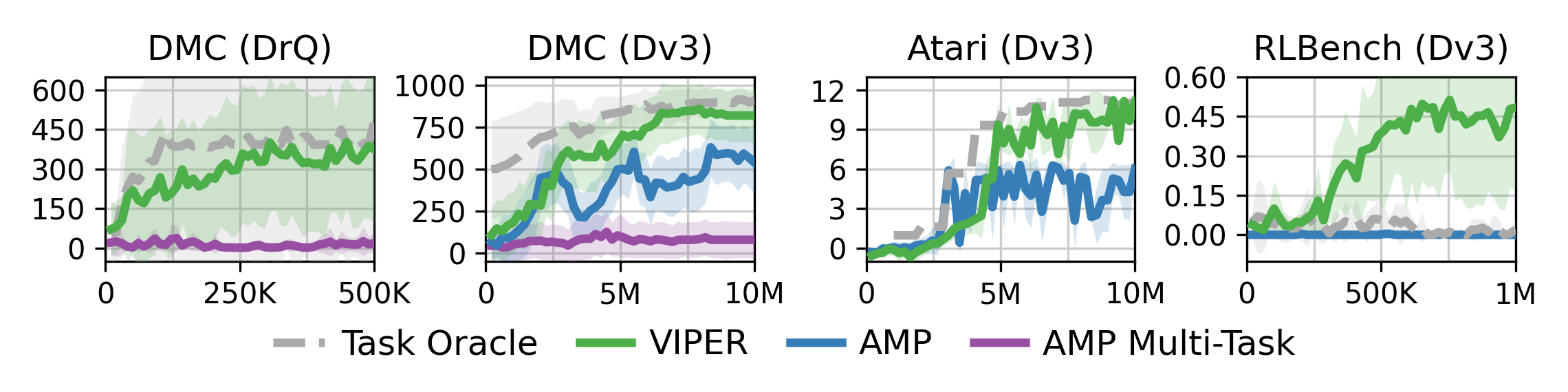

In DMC, VIPER achieves near expert-level performance from pixels with our video prediction rewards alone. Although VIPER slightly underperforms Task Oracle, this is surprising as the Task Oracle uses full state information along with dense task rewards. VIPER outperforms both variants of AMP. Worth noting is the drastic performance difference between the single-task and multi-task AMP algorithms. This performance gap can possibly be attributed to mode collapse, whereby the discriminator classifies all frames for the current task as fake samples, leading to an uninformative reward signal for the agent. Likelihood-based video models, such as VIPER, are less susceptible to mode collapse than adversarial methods.
In Atari, VIPER approaches the performance of the Task Oracle trained with the original sparse task reward, and outperforms the AMP baseline. We found that masking the scoreboard in each Atari environment when training the video model improved downstream RL performance.

For RLBench, VIPER outperforms the Task Oracle because RLBench tasks provide very sparse rewards after long sequences of actions, which pose a challenging objective for RL agents. VIPER instead provides a dense reward extracted from the expert videos, which helps learn these challenging tasks. When training the video model, we found it beneficial to train at a reduced frame rate, accomplished by subsampling video sequences by a factor of 4. Otherwise, we observed the video model would assign high likelihoods to stationary trajectories, resulting in learned policies rarely moving and interacting with the scene. We hypothesize that this may be partially due to the high control frequency of the environment, along with the initial slow acceleration of the robot arm in demonstrations, resulting in very little movement between adjacent frames.

Cross-Embodiment Generalization
We seek to understand how this generalization can be used to learn more general reward functions. We train a model on two datasets of different robot arms, and evaluate the cross-embodiment generalization capabilities of the model. Specifically, we gather demonstrations for 23 tasks on the Rethink Robotics Sawyer Arm, and demonstrations for 30 tasks on the Franka Panda robotic arm, where only 20 tasks are overlapping between arms. We then train a task-conditioned autoregressive video model on these demonstration videos and evaluate the video model by querying unseen arm/task combinations, where a single initial frame is used for open loop predictions.
Sample video model rollouts for in distribution training tasks and an OOD arm/task combination are shown below:



Even though the video model was not directly trained on demon- strations of the Franka Panda arm to solve the saucepan task in RLBench, it is able to generate reasonable trajectories for the arm and task combination
We observe that these generalization capabilities also extend to downstream RL, where we use our trained video model with VIPER to learn a policy for the Franka Robot arm to solve an OOD task without requiring demos for that specific task and arm combination. These results demonstrate a promising direction for future work in applying VIPER to larger scale video models that will be able to better generalize and learn desired behaviors only through a few demonstrations.
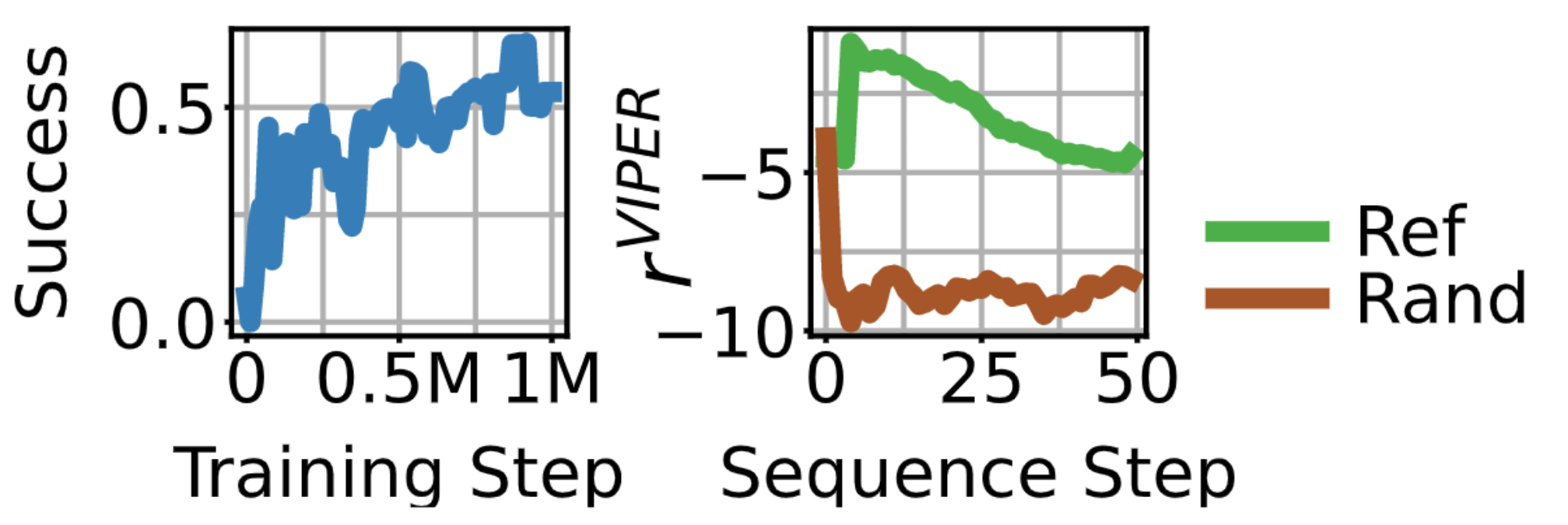
Visualizing Video Model Uncertainty
We can visualize the the uncertainty of the video model by upsampling per-frame log-probabilities for each VQCode. We find that the video model correctly assigns low log probs to trajectories that are not consistent with the reference videos, and high log probs to trajectories that are consistent with the reference videos. We show this for low return trajectories and expert trajectories in the figure below:






Acknowledgements
This work was supported in part by an NSF Fellowship, NSF NRI #2024675, ONR MURI N00014-22-1-2773, Komatsu, and the Vanier Canada Graduate Scholarship. We also thank Google TPU Research Cloud for providing compute resources.
How to cite
-
@article{Escontrela23arXiv_VIPER, journal = {Neural Information Processing Systems}, author = {Escontrela, Alejandro and Adeniji, Ademi and Yan, Wilson and Jain, Ajay and Peng, Xue Bin and Goldberg, Ken and Lee, Youngwoon and Hafner, Danijar and Abbeel, Pieter}, keywords = {Artificial Intelligence (cs.AI)}, title = {Video Prediction Models as Rewards for Reinforcement Learning}, publisher = {arXiv}, copyright = {Creative Commons Attribution 4.0 International}, year = {2023}, eprint = {2305.14343}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, }