

Publication info
-
 International Conference on Intelligent Robots and Systems 2022Best Paper Award finalist,
International Conference on Intelligent Robots and Systems 2022Best Paper Award finalist,(0.6%)
Leveraging adversarial motion priors for robot locomotion
The project page is organized as follows:
- Leveraging adversarial motion priors for robot locomotion
- Overview
- Example behaviors
- Energy efficiency comparison with baselines
- Motion priors substitute the need for complex style rewards or custom action spaces
- More behaviors
Overview
We propose substituting complex reward functions with motion priors learned from a dataset of motion capture demonstrations. A learned style reward can be combined with an arbitrary task reward to train policies that perform tasks using naturalistic strategies. These natural strategies can also facilitate transfer to the real world. We build upon Adversarial Motion Priors - an approach from the computer graphics domain that encodes a style reward from a dataset of reference motions - to demonstrate that an adversarial approach to training policies can produce behaviors that transfer to a real quadrupedal robot without requiring complex reward functions. We also demonstrate that an effective style reward can be learned from a few seconds of motion capture data gathered from a German Shepherd and leads to energy-efficient locomotion strategies with natural gait transitions.
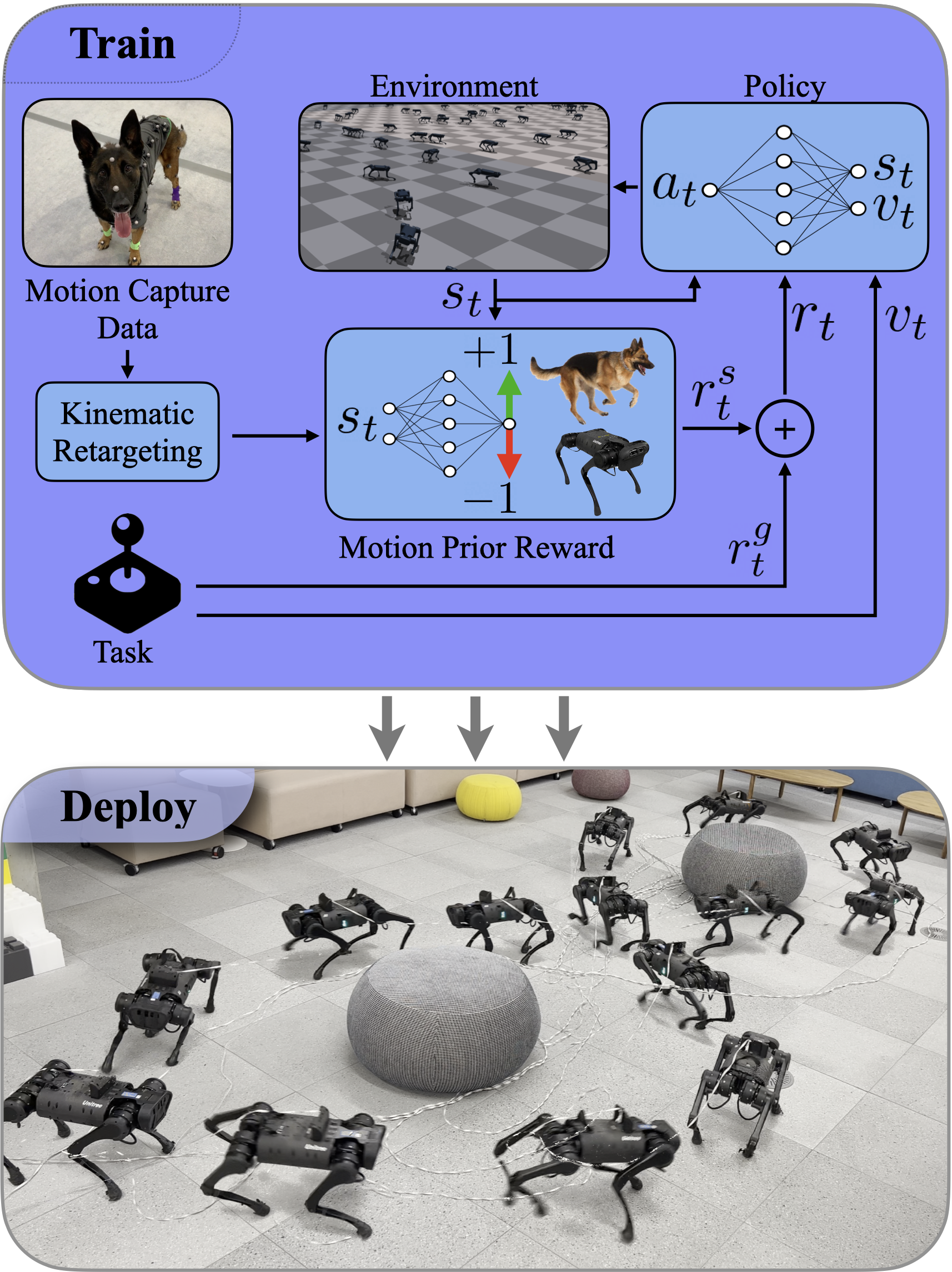
Example behaviors
Energy efficiency comparison with baselines
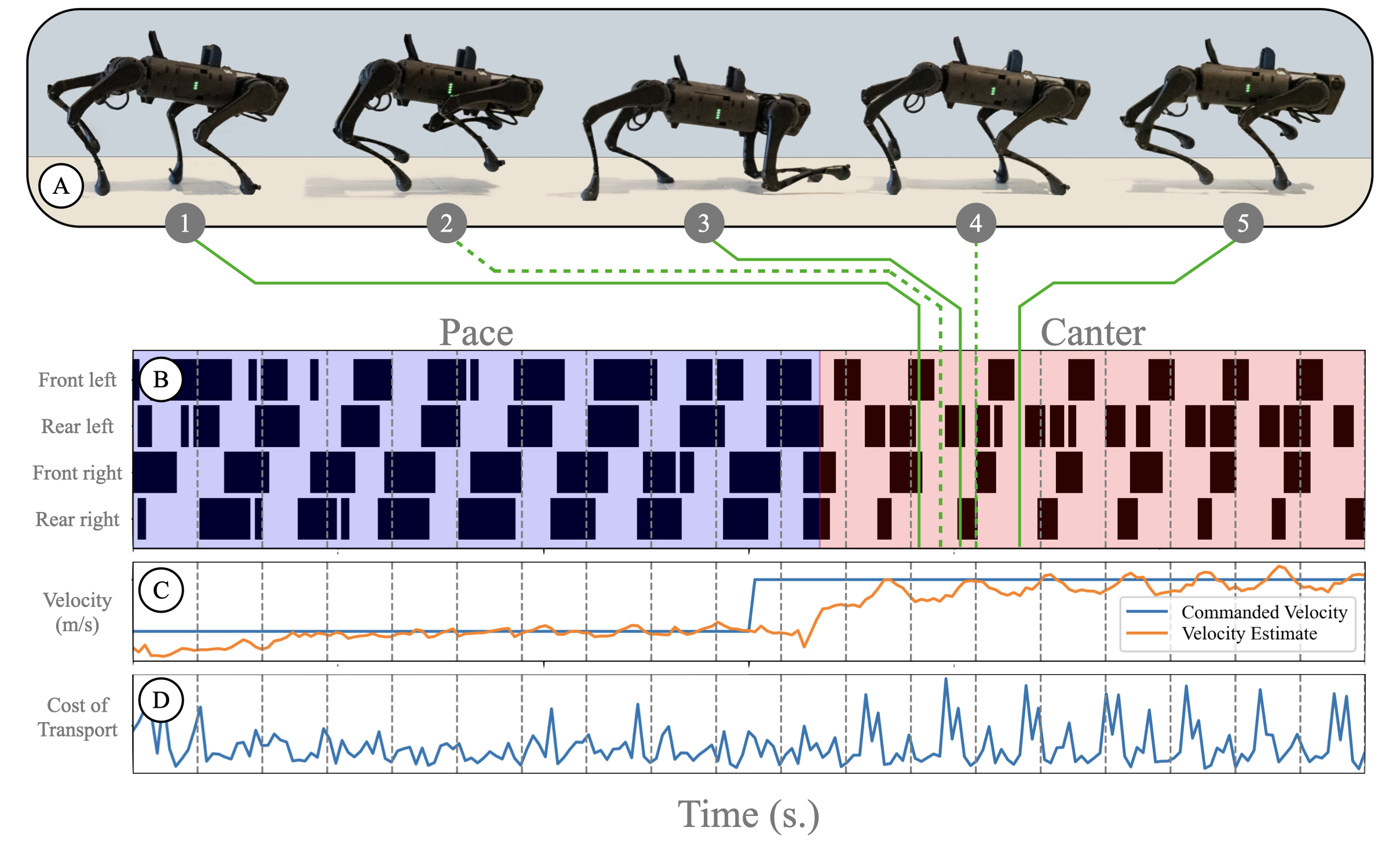
We estimate the Cost of Transport (COT) for a policy trained using Adversarial Motion Priors. COT is a dimensionless quantity commonly used in the field of legged locomotion, as it allows for energy-efficiency comparisons of dissimilar robots or controllers. We utilize the COT to measure the efficiency of different baselines at different speeds.
A policy trained using AMP successfully tracks the desired forward velocity commands while exhibiting a lower COT than competing baselines (see paper). The energy efficiency of policies trained with AMP can likely be attributed to the policy extracting energy-efficient motion priors from the reference data. Millions of years of evolution has endowed dogs with energy-efficient locomotion behaviors. Training with AMP enables the policy to extract some of these energy-efficient strategies from the data. Additionally, animals often perform gait transitions when undergoing large changes in velocity, lowering the cost of transport across different speeds. The same principle applies to policies trained using AMP. The below figure demonstrates the robot transitioning from a pacing motion to a canter motion when the desired velocity jumps from 1 m/s to 2 m/s. While pacing is the optimal gait at low speeds, entering a canter motion with a flight phase is a more energy-efficient option at high speeds.
Motion priors substitute the need for complex style rewards or custom action spaces

Complex reward functions with tens of terms or custom action spaces are normally used to ensure that policies transfer from simulation to reality. The terms in the complex reward function are often used to disincentivize the policy from learning behaviors which exploit the inaccurate simulation dynamics or are inefficient. While policies trained in this manner transfer to hardware, it is often tedious to hand-design giant reward functions and weight their individual components. Additionally, these hand-designed reward functions are often platform-dependent and don't work well across all tasks. Alternatively, researchers have explored defining custom action spaces such as trajectory generators. These hand-defined action spaces prevent the robot from learning undesired behaviors, but often limit the performance of the resulting policy and require significant engineering effort to develop. Adversarial Motion Priors provide a promising alternative to these approaches. Using a small amount of reference data, we can learn a style reward that encourages the agent to learn efficient and aesthetically pleasing behaviors with minimal engineering effort.
More behaviors
Informal race between Fu et al. (left) and AMP Policy (right)
A user can use a joystick policy to provide the policy with command velocities. The AMP controller produces precise behaviors which enable the robot to navigate a course with tight turns.
AMP policy performing a figure eight maneuver, which requires interpolating within a range of angular velocities.
Acknowledgements
The authors would like to thank Adam Lau, Justin Kerr, Lars Berscheid, and Chung Min Kim for their helpful contributions and discussions.
How to cite
-
@article{Escontrela22arXiv_AMP_in_real, journal = {International Conference on Intelligent Robots and Systems}, doi = {10.48550/ARXIV.2203.15103}, author = {Escontrela, Alejandro and Peng, Xue Bin and Yu, Wenhao and Zhang, Tingnan and Iscen, Atil and Goldberg, Ken and Abbeel, Pieter}, keywords = {Artificial Intelligence (cs.AI), Robotics (cs.RO), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions}, publisher = {arXiv}, year = {2022}, copyright = {Creative Commons Attribution 4.0 International}, }