Train robot policies at 100K+ steps/second in photorealistic 3D environments captured from iPhone videos, datasets, or AI-generated worlds.
🎮 Try It Yourself
Explore photorealistic 3D environments where our robot policies learn to navigate. Each scene—from real-world iPhone captures to AI-generated landscapes—is rendered using 3D Gaussian Splatting and fully interactive in your browser.
👇 Select a category, pick a scene, and see the robot's view as it moves through the world
Interactive demos made possible by Spark, Viser, and Brent Yi
Note: Some examples may be slow to load
🎬 Scene Showcase
See gaussian splats from our dataset. Scenes are from the GrandTour subcollection.
Overview
Training vision-based robot policies requires massive amounts of diverse, high-quality data. Traditional simulators struggle to provide photorealistic visual experiences at the scale needed for modern reinforcement learning, forcing researchers to choose between visual fidelity and training throughput.
We present GaussGym, a novel approach that integrates 3D Gaussian Splatting as a drop-in renderer within vectorized physics simulators such as IsaacGym. This integration enables unprecedented speed—exceeding 100,000 steps per second on consumer GPUs—while maintaining photorealistic visual fidelity.
Key capabilities:
- Photorealistic rendering using 3D Gaussian Splatting at massive scale
- Diverse scene creation from iPhone scans, datasets (GrandTour, ARKit), and generative video models (Veo)
- Sim2real transfer with motion blur, camera randomization, and intrinsic jitter
- Rich sensing beyond RGB: depth maps, heightmaps, and terrain-based rewards
- Tasks are provided out of the box, including pursuit tasks and goal reaching.
This work bridges high-throughput simulation and high-fidelity perception, advancing scalable and generalizable robot learning. All code and data are open-sourced for the community to build upon.
Gauss Gym provides tooling to extract scenes from a variety of datasets, including iPhone scans, existing image datasets (e.g. GrandTour, ARKitScenes), and even generative video models like Veo.
Lowering the Visual Sim2Real Gap
A critical challenge in sim-to-real transfer is the visual gap between simulated and real-world images. Real cameras introduce artifacts like motion blur, lens distortion, and varying intrinsics that are rarely modeled in traditional simulators. GaussGym addresses this by simulating these effects efficiently during training.
Motion Blur: Real cameras capture images over finite exposure times, creating motion blur when the robot or camera moves. We simulate this by alpha-blending rendered images along the camera’s twist vector, parameterized by shutter speed. This can be randomized during training to improve robustness to varying lighting conditions and motion speeds.
Camera Randomization: We support randomization of camera pose, intrinsics (focal length, principal point), and extrinsics to ensure policies generalize across different camera configurations. All randomizations run efficiently within the vectorized renderer.
Terrain-Aware Rewards: Beyond visual rendering, GaussGym integrates with NVIDIA Warp to provide heightmap measurements directly from the 3D scene geometry. This enables computation of terrain-based rewards and geometric constraints without expensive raycasting.

Motion blur achieved by alpha-blending images along the cameras twist vector and is parameterized by the shutter speed, which can also be randomized.
Extracting scenes from videos
Creating diverse, high-quality training environments has traditionally been a bottleneck in robot learning. Manual scene creation is labor-intensive, while existing datasets offer limited diversity. GaussGym dramatically simplifies this process by automatically extracting simulation-ready 3D scenes from videos and images.
Automated Scene Pipeline: Our pipeline leverages recent advances in Structure from Motion (SfM), Surface Reconstruction, and Differentiable Rendering. Input images are processed through VGGT to extract metric poses and dense point clouds with normals. These are then used to: (1) reconstruct high-resolution collision meshes for physics simulation with NKSR, and (2) train 3D Gaussian Splatting models with gsplat for photorealistic rendering.
From Capture to Sim in Minutes: What previously required days of manual modeling now happens automatically. Simply capture a video with your iPhone, run it through our pipeline, and get a simulation-ready scene complete with both visual rendering and collision geometry. This enables rapid iteration and massive scaling to thousands of diverse environments.
Beyond Real-World Capture: Our pipeline also supports extracting scenes from generative video models like Veo. Users can describe desired training scenarios via text prompts (e.g., “a crystal cave with glowing formations”), generate videos, and automatically extract 3D scenes for simulation. This opens up entirely new possibilities for training in environments that don’t exist in the real world.
Rich Multi-Modal Sensing
While photorealistic RGB rendering is essential for vision-based policies, many robotics tasks benefit from additional sensing modalities. GaussGym efficiently renders depth maps alongside RGB images, enabling richer perception without sacrificing performance.
Depth Rendering: Using the same 3D Gaussian Splatting representation, we render per-pixel depth maps that provide geometric understanding of the scene. This is particularly valuable for:
- Navigation tasks where obstacle distance matters
- Manipulation requiring precise geometric reasoning
- Multi-modal policies that fuse RGB and depth for robustness
Performance: Depth rendering adds minimal overhead to the already fast RGB rendering pipeline, maintaining the 100K+ steps/second throughput that makes large-scale training practical.
Sensor Flexibility: The depth maps can be configured to match real sensor characteristics (range limits, noise patterns) to further improve sim-to-real transfer.
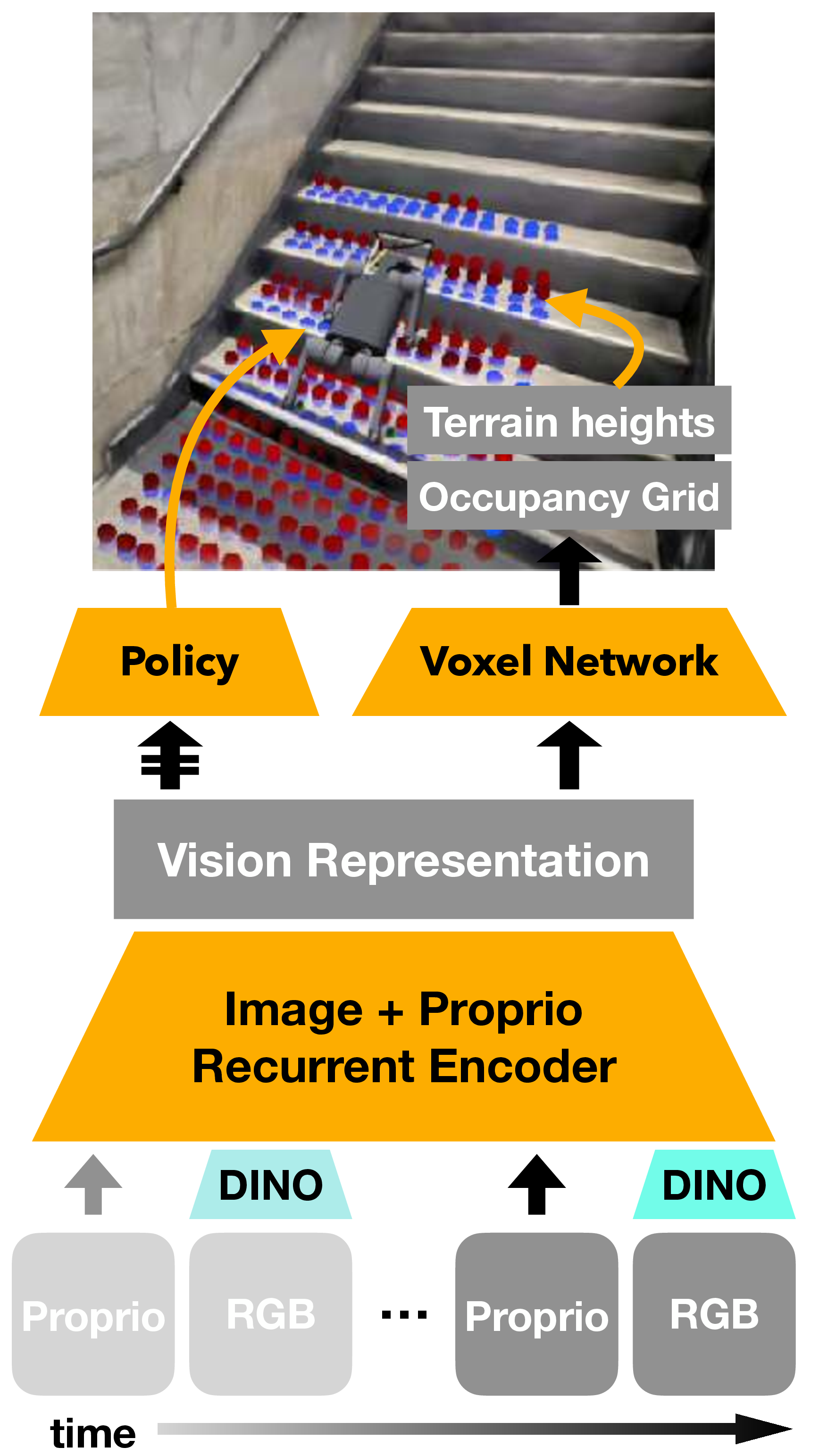
Policy Learning
Our vision-based policy uses a recurrent encoder that fuses visual and proprioceptive observations over time. At each timestep, DinoV2 embeddings from RGB images are concatenated with proprioceptive measurements and processed through an LSTM, creating a compact latent representation that captures temporal dynamics and visual semantics. We use LSTM instead of transformers to ensure fast inference on-robot.
This shared representation feeds two specialized heads:
Voxel Prediction Head: Unflattens the latent vector into a 3D grid and applies transposed convolutions to predict dense volumetric occupancy and terrain heights, forcing the network to learn scene geometry.
Policy Head: A second LSTM processes the latent representation and outputs parameters of a Gaussian distribution over joint position offsets.
Sim2Real Transfer
We provide deployment code to evaluate learned policies on hardware. We also validate our architecture on the Unitree A1 quadrupedal robot, demonstrating perceptive locomotion on 17cm stairs.


How to cite
-
@article{Escontrela25arXiv_GaussGym, journal = {CoRR}, author = {Escontrela, Alejandro and Kerr, Justin and Allshire, Arthur and Frey, Jonas and Duan, Rocky and Sferrazza, Carmelo and Abbeel, Pieter}, keywords = {Artificial Intelligence (cs.AI), Robotics (cs.RO)}, title = {GaussGym: An Open-Source Real-To-Sim Framework for Learning Locomotion from Pixels}, publisher = {arXiv}, copyright = {Creative Commons Attribution 4.0 International}, year = {2025}, eprint = {2510.15352}, archiveprefix = {arXiv}, primaryclass = {cs.RO}, }
Acknowledgements
We would like to thank Brent Yi, Angjoo Kanazawa, Marco Hutter, Karen Liu, and Guanya Shi for their valuable feedback and support. This work was supported in part by an NSF Graduate Fellowship, the ONR MURI N00014-22-1-2773, the BAIR Industrial Consortium, and Amazon. We also thank NVIDIA for providing compute resources through the NVIDIA Academic DGX Grant.